IBM Parallel Environment
User and Administrator Guide
Overview
User Tools
System Administration
Overview
This document describes the unique features of Slurm on the IBM computers with the Parallel Environment (PE) software. You should be familiar with the Slurm's mode of operation on Linux clusters before studying the relatively few differences in operation on systems with PE, which are described in this document.
Note that Slurm is designed to be a replacement for IBM's LoadLeveler. They are not designed to concurrently schedule resources. Slurm provides manages network resources and provides the POE command with a library that emulates LoadLeveler functionality.
User Tools
The normal set of Slurm user tools: srun, scancel, sinfo, squeue, scontrol, etc. provide all of the expected services. The onl. Slurm command not supported is sattach. Job steps are launched using the srun command, which translates its options and invokes IBM's poe command. The poe command actually launches the tasks. The poe command may also be invoked directly if desired. The actual task launch process is as follows:
- Invoke srun command with desired options.
- The srun command creates a job allocation (if necessary).
- The srun command translates its options and invokes the poe command.
- The poe command loads a Slurm library that provides various resource management functionality.
- The poe command, through the Slurm library, creates a Slurm step allocation and launches a process named "pmdv12" on the appropriate compute nodes. Note that the "v12" on the end of the process name represents the version number of the "pmd" process and is subject to change.
- The poe command interacts with the pmdv12 process to launch the application tasks, handle their I/O, etc. Since the task launch procedure occurs outside of Slurm's control, none of the normal task-level Slurm support is available.
- The poe command, through the Slurm library, reports the completion of the job step.
Network Options
Each job step can specify it's desired network options. For example, one job step may use IP mode communications and the next use User Space (US) mode communications. Network specifications may be specified using srun's --network option or the SLURM_NETWORK environment variable. Supported network options include:
- Network protocol
- ip Internet protocol, version 4
- ipv4 Internet protocol, version 4 (default)
- ipv6 Internet protocol, version 6
- us User Space protocol, may be combined with ibv4 or ipv6
- Programming interface
- lapi Low-level Application Programming Interface
- mpi Message Passing Interface (default)
- pami Parallel Active Message Interface
- pgas Partitioned Global Address Programming
- shmem OpenSHMEM interface
- test Test Protocol
- upc Unified Parallel C Interface
- Other options
- bulk_xfer [=resources] Enable bulk transfer of data using Remote Direct-Memory Access (RDMA). The optional resources specification is a numeric value which can have a suffix of "k", "K", "m", "M", "g" or "G" for kilobytes, megabytes or gigabytes. NOTE: The resources specification is not supported by the underlying IBM infrastructure as of Parallel Environment version 2.2 and no value should be specified at this time.
- cau=count Specify the count of Collective Acceleration Units (CAU) required per programming interface. Default value is zero. Applies only to IBM Power7-IH processors. POE requires that if cau has a non-zero value then us, devtype=IB or devtype=HFI must be explicitly specified otherwise the request may attempt to allocate CAU with IP communications and fail.
- devname=name Specify the name of an individual network adapter to use. For example: "eth0" or "mlx4_0".
- devtype=type Specify the device type to use for communications. The supported values of type are: "IB" (InfiniBand), "HFI" (P7 Host Fabric Interface), "IPONLY" (IP-Only interfaces), "HPCE" (HPC Ethernet), and "KMUX" (Kernel Emulation of HPCE). The devices allocated to a job must all be of the same type. The default value depends upon depends upon what hardware is available and in order of preferences is IPONLY (which is not considered in User Space mode), HFI, IB, HPCE, and KMUX.
- immed=count Specify the count of immediate send slots per adapter window. Default value is zero. Applies only to IBM Power7-IH processors.
- instances=count Specify number of network connections for each task on each network connection. The default instance count is 1.
- sn_all Use all available switch adapters (default). This option can not be combined with sn_single.
- sn_single Use only one switch adapters. This option can not be combined with sn_all. If multiple adapters of different types exist, the devname and/or devtype option can also be used to select one of them.
NOTE: Slurm supports the values listed above, and does not support poe user_defined_parallelAPI values.
Examples of network option use:
--network=sn_all,mpi
Allocate one switch window per task on each node and every network supporting
MPI.
--network=sn_all,mpi,bulk_xfer,us
Allocate one switch window per task on each node and every network supporting
MPI and user space communications. Reserve resources for RDMA.
--network=sn_all,instances=3,mpi
Allocate three switch window per task on each node and every network supporting
MPI.
--network=sn_all,mpi,pami
Allocate one switch window per task on each node and every network supporting
MPI and a second window supporting PAMI.
--network=devtype=ib,instances=2,lapi,mpi
On every InfiniBand network connection, allocate two switch windows each for
both lapi and mpi interfaces. If each node has one InfiniBand network connection,
this would result in four switch windows per task.
NOTE: Switch resources on a node are shared between all job steps on that node. If a job step can not be initiated due to insufficient switch resources being available, that job step will periodically retry allocating resources for the lifetime of the job unless srun's --immediate option is used.
Debugging
Most debuggers require detailed information about launched tasks such as
host name, process ID, etc. Since that information is only available from
poe (which launches those tasks), the srun command wrapper can not be used
for most debugging purposes. You or the debugging tool must invoke the poe
command directly. In order to facilitate the direct use of poe, srun's
--launch-cmd option may be used with the options normally used.
srun will then print the equivalent poe command line, which
can subsequently be used with the debugger. The poe options must be explicitly
set even if the command is executed from within an existing Slurm allocation
(i.e. from within an allocation created by the salloc or sbatch command).
Checkpoint
Checkpoint/restart is only supported with LoadLeveler.
Unsupported Options
Some Slurm options can not be supported by PE and the following srun options are silently ignored:
- -D, --chdir (set working directory)
- -K, --kill-on-bad-exit (terminate step if any task has a non-zero exit code)
- -k, --no-kill (set to not kill job upon node failure)
- --ntasks-per-core (number of tasks to invoke per code)
- --ntasks-per-socket (number of tasks to invoke per socket)
- -O, --overcommit (over subscribe resources)
- --resv-ports (communication ports reserved for OpenMPI)
- --signal (signal to send when near time limit and the remaining time required)
- --sockets-per-node (number of sockets per node required)
- --task-epilog (per-task epilog program)
- --task-prolog (per-task prolog program)
- -u, --unbuffered (avoid line buffering)
- -W, --wait (specify job swait time after first task exit)
- -Z, --no-allocate (launch tasks without creating job allocation>
A limited subset of srun's --cpu-bind options are supported as shown below. If the --cpus-per-task option is not specified, a value of one is used by default. Note tha. Slurm's mask_cpu and map_cpu options are not supported, nor are options to bind to sockets or boards.
| Slurm option | POE equivalent |
| --cpu-bind=threads --cpus-per-task=# | -task_affinity=cpu:# |
| --cpu-bind=cores --cpus-per-task=# | -task_affinity=core:# |
| --cpu-bind=rank --cpus-per-task=# | -task_affinity=cpu:# |
In addition, file name specifications with expression substitution (e.g. file names including "%j" for job_ID, "%J" for job_ID.step_ID, "%s" for step_ID, "%t" for task_ID, or "%n" for node_ID) are not supported. This effects the following options:
- -e, --error
- -i, --input
- -o, --output
For the srun command's --multi-prog option (Multiple Program, Multiple Data configurations), the command file will be translated from Slurm's format to a POE format. POE does not suppor. Slurm expressions in the MPMD configuration file (e.g. "%t" will not be replaced with the task's number and "%o" will not be replaced with the task's offset within this range). The command file will be stored in a temporary file in the ".slurm" subdirectory of your home directory. The file name will have a prefix of "slurm_cmdfile." followed by srun's process id. If the srun command does not terminate gracefully, this file may persist after the job step's termination and not be purged. You can find and purge these files using commands of the form shown below. You should only purge older files, after their job steps are completed.
$ ls -l ~/.slurm/slurm_cmdfile.* $ rm ~/.slurm/slurm_cmdfile.*
The -L/--label option differs slightly in that when the output from multiple tasks are identical, they are combined on a single line with the prefix identifying which task(s) generated the output. In addition, there is a colon but no space between the task IDs and output. For example:
# Slurm OUTPUT 0: foo 1: foo 2: foo 0: bar 1: barr 2: bar # POE OUTPUT 0-2:foo 0 2:bar 1:barr
In addition, when srun's --multi-prog option (for Multiple Program, Multiple Data configurations) is used with the -L/--label option then a job step ID, colon and space will precede the task ID and colon. For example:
# Slurm OUTPUT 0: zero 1: one 2: two # POE OUTPUT (FOR STEP ID 1) 1: 0: zero 1: 1: one 1: 2: two
The srun command is not able to report task status upon receipt of a SIGINT signal (ctrl-c interrupt from keyboard), however two SIGINT signals within a one second interval will terminate the job as on other Slurm configurations.
Environment Variables
Since Slurm is not directly launching user tasks, the following environment variables are NOT available with POE:
- SLURM_CPU_BIND_LIST
- SLURM_CPU_BIND_TYPE
- SLURM_CPU_BIND_VERBOSE
- SLURM_CPUS_ON_NODE
- SLURM_GTIDS
- SLURM_LAUNCH_NODE_IPADDR
- SLURM_LOCALID
- SLURM_MEM_BIND_LIST
- SLURM_MEM_BIND_TYPE
- SLURM_MEM_BIND_VERBOSE
- SLURM_NODEID
- SLURM_PROCID
- SLURM_SRUN_COMM_HOST
- SLURM_SRUN_COMM_PORT
- SLURM_TASK_PID
- SLURM_TASKS_PER_NODE
- SLURM_TOPOLOGY_ADDR
- SLURM_TOPOLOGY_ADDR_PATTERN
Note that POE sets a variety of environment variables that provide similar information to some the missing Slurm environment variables. Particularly note the following environment variables:
- MP_I_UPMD_HOSTNAME (local hostname)
- MP_CHILD (global task ID)
Gang Scheduling
Slurm can be configured to gang schedule (time slice) parallel jobs by alternately suspending and resuming them. Depending upon the number of jobs configured to time slice and the time slice interval (as specified in the slurm.conf file using the OverSubscribe and SchedulerTimeSlice options), the job may experience communication timeouts. Set the environment variable MP_TIMEOUT to specify an appropriate communication timeout value. Note that the default timeout is 150 seconds. See Gang Scheduling for more information.
export MP_TIMEOUT=600
Other User Notes
POE can not support a step ID of zero. In POE installations, a job's first step ID will be 1 rather than 0.
Since the Slurm step launches the PE PMD process instead of the users tasks the exit code stored in accounting will be that of the PMD instead of the users tasks. The exit code of the job allocation if started with srun will be correct as we will grab the exit code from the wrapped poe.
Use of the srun command rather than the poe command is recommended to launch tasks. If the poe command is used with a hostlist file (e.g. "-hfile" option or "MP_HOSTFILE" environment variable or a "host.list" file in the current working directory), the resd option must be set to yes (e.g. "-resd yes" option or "MP_RESD=yes" environment variable).
System Administration
There are several critical Slurm configuration parameters for use with PE. These configuration parameters should be set in your slurm.conf file. LaunchType defines the task launch mechanism to be used and must be set to launch/poe. This configuration means that poe will be used to launch all applications. SwitchType defines the mechanism used to manage the network switch and it must be set to switch/nrt and use IBM's Network Resource Table (NRT) interface on ALL nodes in the cluster (only a few of them will actually interact with IBM's NRT library, but all need to work with the NRT data structures). Task launch is slower in this environment than with a typical Linux cluster and the MessageTimeout must be configured to a sufficiently large value so that large parallel jobs can be launched withou. Slurm's job step credentials expiring. When switch resources are allocated to a job, all processes spawned by that job must be terminated before the switch resources can be released for use by another program. This means that reliable tracking of all spawned processes is critical for switch use. Use of ProctrackType=proctrack/cgroup is strongly recommended. Use of any other process tracking plugin significantly increases the likelihood of orphan processes that must be manually identified and killed in order to release switch resources. While it is possible to to configure distinct NodeName and NodeHostName parameters for the compute nodes, this is discouraged for performance reasons (the switch/nrt plugin is not optimized for such a configuration).
# Excerpt of slurm.conf LaunchType=launch/poe SwitchType=switch/nrt MessageTimeout=30 ProctrackType=proctrack/cgroup
In order for these plugins to be built, the locations of the POE Resource Manager header file (permapi.h) the NRT header file (nrt.h) and NRT library (libnrt.so) must be identified at the time the Slurm is built. The header files are needed at build time to get NRT data structures, function return codes, etc. The NRT library location is needed to identify where the library is to be loaded from by Slurm's switch/nrt plugin, but the library is only actually when needed and only by the slurmd daemon.
Slurm searches for the header files in the /usr/include directory by default. If the files are not installed there, you can specify a different location using the --with-nrth=PATH option to the configure program, where "PATH" is the fully qualified pathname of the parent directory(ies) of the nrt.h and permapi.h files. Slurm searches for the libnrt.so file in the /usr/lib and /usr/lib64 directories by default. If the file is not installed there, you can specify a different location using the --with-nrtlib=PATH option to the configure program, where "PATH" is the fully qualified pathname of the parent directory of the libnrt.so file. Alternately these values may be specified in your ~/.rpmmacros file. For example:
%_with_nrth "/opt/ibmhpc/pecurrent/base/include" %_with_libnrt "/opt/ibmhpc/pecurrent/base/intel/lib64"
IMPORTANT:The poe command interacts with Slurm by loading a Slurm library providing a variety of functions for its use. The library name is "libpermapi.so" and it is in installed with the other Slurm libraries in the subdirectory "lib/slurm". You must modify the link of /usr/lib64/libpermapi.so to point to the location of the slurm version of this library.
Modifying the "/etc/poe.limits" file is not enough. The poe command is loading and using the libpermapi.so library initially from the /usr/lib64 directory. It later reads the /etc/poe.limits file and loads the library listed there. In order for poe to work with Slurm, it needs to use the "libpermapi.so" generated by Slurm for all of its functions. Until poe is modified to only load the correct library, it is necessary for /usr/lib64/libpermapi.so to contain Slurm's library or a link to it.
If you are having problems running on more than 32 nodes this is most likely your issue.
Changes to the count of dynmamic switch windows necessitate cold-starting Slurm (without jobs). The procedure is as follows:
- Prevent new jobs from being started (e.g. Drain the compute nodes).
- Cancel all jobs.
- Change the dynamic window count on the compute nodes.
- Restart Slurm daemons without preserving state (e.g. "/etc/init.d/slurm startclean" or initiate the daemons using the "-c" option).
Job Scheduling
Slurm can be configured to gang schedule (time slice) parallel jobs by alternately suspending and resuming them. Depending upon the number of jobs configured to time slice and the time slice interval (as specified in the slurm.conf file using the OverSubscribe and SchedulerTimeSlice options), the job may experience communication timeouts. Set the environment variable MP_TIMEOUT to specify an appropriate communication timeout value. Note that the default timeout is 150 seconds. See Gang Scheduling for more information.
export MP_TIMEOUT=600
Slurm also can support long term job preemption with IBM's Parallel Environment. Job's can be explicitly preempted and later resumed using the scontrol suspend <jobid> and scontrol resume <jobid> commands. This functionality relies upon NRT functions to suspend/resume programs and reset MPI timeouts. Note tha. Slurm supports the preemption only of whole jobs rather than individual job steps. A suspended job will relinquish CPU resources, but retain memory and switch window resources. Note that the long term suspension of jobs with any allocated Collective Acceleration Units (CAU) is disabled and an error message to that effect will be generated in response to such a request. In addition, version 1200 or higher of IBM's NRT API is required to support this functionality.
Cold Starting
If the slurmctld daemon is cold started (without saved state), then information about previously allocated network resources is lost. Slurm will release those resources to the best of its ability based upon information available from the Network Resource Table (NRT) library functions. These function provide sufficient information to release all resources except for CAU on a Torrent network (e.g. a PERCS system). In order to release CAU, it is necessary to cold start the Protocol Network Services Daemon (PNSD) on compute nodes following the sequence shown below.
Stop Slurm daemons: /etc/init.d/slurm stop Stop PNSD: stopsrc -s pnsd Start PNSD clean: startsrc -s pnsd -a -c Start Slurm daemons clean: /etc/init.d/slurm startclean
Design Notes
It is necessary for all nodes that can be used for scheduling a single job have the same network adapter types and count. For example, if node "tux1" has two ethernet adapters then the node "tux2" in the same cluster must also have two ethernet adapters on the same networks or be in a different Slurm partition so that one job can not be allocated resources on both nodes. Without this restriction, a job may allocated adapter resources on one node and be unable to allocate the corresponding adapter resources on another node.
It is possible to configure Slurm and LoadLeveler to simultaneously exist on a cluster, however each scheduler must be configured to manage different compute nodes (e.g. LoadLeveler can manage compute nodes "tux[1-8]" and Slurm can manage compute nodes "tux[9-16]" on the same cluster). In addition, the /etc/poe.limits file on each node must identify the MP_PE_RMLIB appropriate for that node (e.g. IBM's or Slurm's libpermapi.so). If Slurm and LoadLeveler are configured to simultaneously manage the same nodes, you should expect both resource managers to try assigning the same resources. This will result in job failures.
The srun command uses the launch/poe plugin to launch the poe program. Then poe uses the launch/slurm plugin to launch the "pmd" process on the compute nodes, so two launch plugins are actually used.
Depending upon job size and network options, allocating and deallocating switch resources can take multiple seconds per node and the process of launching applications on multiple nodes is not well parallelized. This is outside of Slurm's control.
The two figures below show a high-level overview of the switch/nrt and launch/poe plugins. A typical Slurm installation with IBM PE would make use of both plugins, but the operation of each is shown independently for improved clarity. Note the the switch/nrt plugin is needed by not only the slurmd daemon, but also the slurmctld daemon (for managing switch allocation data structures) and the srun command (for packing and unpacking switch allocation information used at task launch time). In figure 2, note that the libpermapi library issues the job and job step creation requests. The srun command is an optional front-end for the poe command and the poe command can be invoked directly by the user if desired.
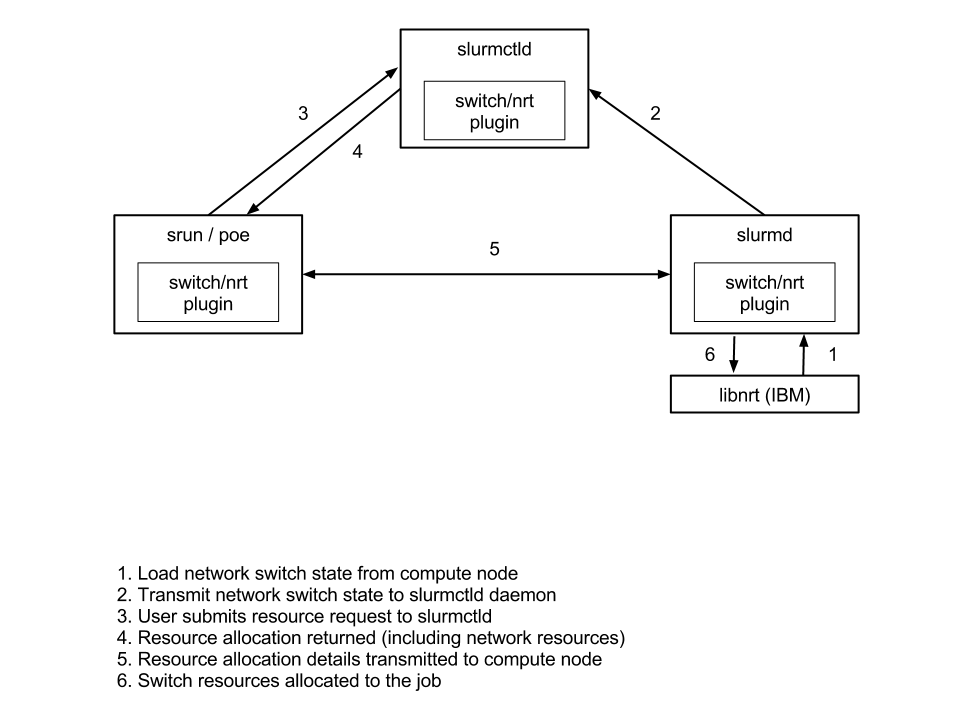
Figure 1: Use of the switch/nrt plugin
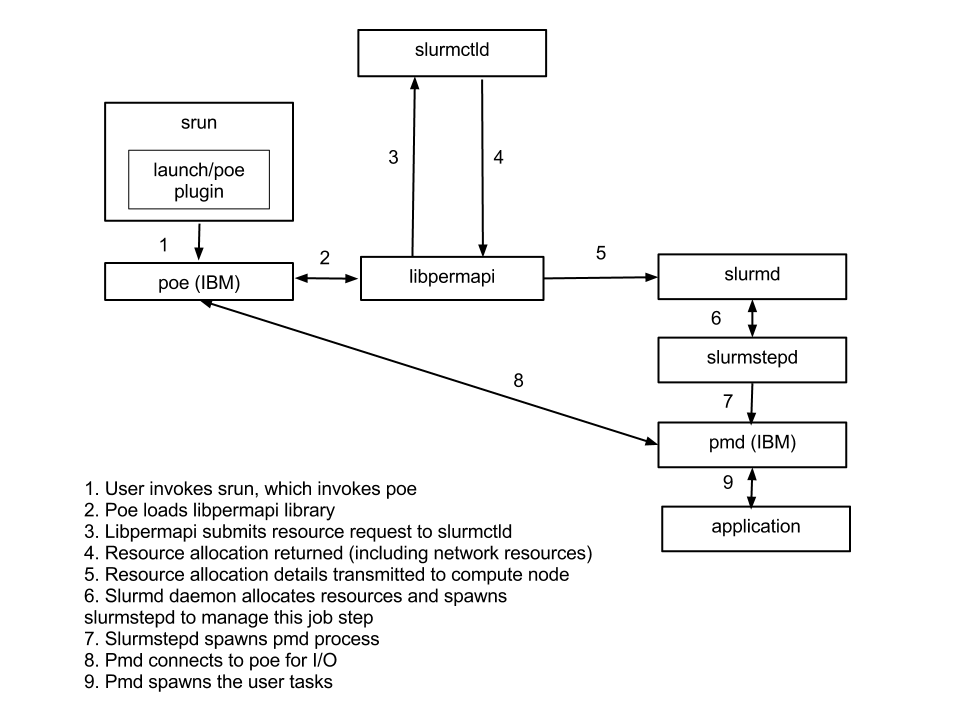
Figure 2: Use of the launch/poe plugin
Debugging Notes
It is possible to generate detailed logging of all switch/nrt actions and data by configuring DebugFlags=switch.
The environment variable MP_INFOLEVEL can be used to enable the logging of POE debug messages. To enable fairly detailed logging, set MP_INFOLEVEL=6.
The Protocol Network Services Daemon (PNSD) manages the Network Resource Table (NRT) information on each node. It's logs are written to the file /tmp/serverlog, which may be useful to diagnose problems. In order to execute PNSD in debug node (for extra debugging information), run the following commands as user root:
stopsrc -s pnsd startsrc -s pnsd -a -D
Last modified 31 March 2016